
Part one of this article introduced the idea that bookmaker’s take positions on point spread markets due to the betting market’s overconfidence on favourites. Part two uses recent NBA betting data to try and answers that question. Read on to find out more.

Do bookmakers take positions in a point spread betting market? In the first part of this two-part betting article I proposed a thought experiment that would account for why they might, and reviewed evidence from the economist Stephen Levitt that suggested bookmakers are manipulating NFL spread prices with a view to exploiting bettors’ preference for backing favourites to cover the spread to increase their profits.
Such systematic bias can be explained by intuitive confidence: the more confidence a bettor has that a team will win (the greater the perceived favouritism), the more likely it is that they will also believe that the team will cover the point spread.
Levitt had found that not only do 60% of bettors prefer backing the favourite in NFL point spread markets, but that those favourites only cover the spread 48% of the time. For a bookmaker with a theoretical margin of 2.5%, such distribution of action would see their profits increase to 3.3%.
Now, I will investigate whether a similar bias can be found in more recent point spread data set from the NBA betting market.
What data are we looking at?
For this analysis I have used a 12-season data set of NBA scores and lines made available by Sportsbook Reviews. The analysis period covers the dates 30th October 2007 to 5th May 2019 and includes 15,508 NBA matches. The spread values I have used are those at market closing.
By choosing different points handicap thresholds to test after we have plotted the data, we run the risk of arbitrarily choosing values that help us fit the hypothesis to the data, when we should really be fitting the data to the hypothesis.
No actual prices have been provided, but the assumption must be that on average the spreads represented 50-50 propositions (1.95/1.95 or 1.91/1.91 for example, -105/-105 or -110/-110 in US odds notation, after the margin is applied). If that assumption is valid, actual prices aren’t necessary for the analysis which follows.
Sportsbook Reviews report that prior to 2015, spread values come from 5Dimes, Betonline, Bookmaker, Heritage, Pinnacle and Sportsbook.com, thereafter from Westgate Superbook with supplements from 5Dimes and Bookmaker. More precise information on which individual spreads come from which specific bookmaker is not made available.
Of the 15,508 matches, 15,311 of those had a handicap favourite at market closing (where the handicap for one of the sides was ≤ -0.5). In 254 of those matches, the favourite (and obviously the underdog as well) exactly covered the point spread. For the remaining 15,057 matches, 7,541, or 50.08%, of the favourites covered the spread, with 7,516, or 49.92% of underdogs doing likewise. The difference from an expectation of 50-50 has a chi-square test p-value of 84%. In other words, there is no statistically significant difference from no systematic bias whatsoever. So much for the 48%.
Drilling down into the spreads
This finding is hardly replicative of Levitt’s NFL analysis. However, let’s not give up hope of finding a bias just yet. Remember that the explanation from intuitive confidence suggests that the greater the Money Line favouritism, the more likely it is that a bettor will choose to back the favourite on the spread market also, encouraging bookmakers to manipulate their spreads for the larger points handicaps.
The chart below shows the cumulative percentage of favourites covering the spread with matches ordered by points handicap, and the largest handicap magnitudes first. Obviously, the x-axis scale is not linear since there are far fewer large points handicaps than small ones.
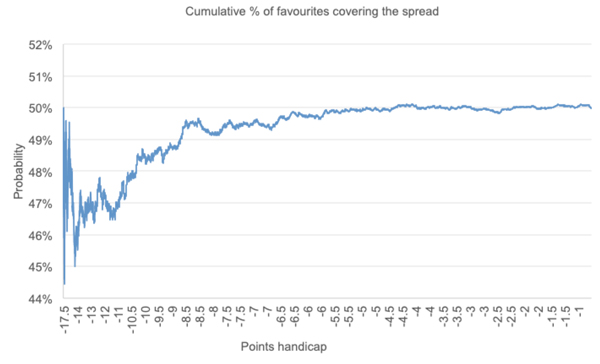
Ignoring the largest handicaps where the small sample size increases variance considerably, the data shows clear evidence of a point spread bias, albeit one that has disappeared by the time we reach handicaps of zero with teams equally rated. For example, the 1,303 matches that had closing handicap magnitudes ≥ 12 saw just 47.0% of the favourites covering them. For the 2,600 matches that had closing handicap magnitudes ≥ 10, 48.3% of the favourites covered the spread. And for the 4,701 matches that had closing handicap magnitudes ≥ 8, the figure was 49.4%.
Systematic or random?
The question now is whether this bias is meaningful and statistically significant or just a lucky finding arising from small sample size. Considering the handicap magnitudes ≥ 12, a t-test confirms that the probability that 47% of the favourites would cover the spread (given an expectation of 50%) would happen by chance is just 0.3%.
Typically, this would be regarded as statistically significant (p-values < 5% or 1% are usually regarded as critical benchmarks for statistical significance), and we would rule out the null hypothesis that there should be no bias in favour of a different one where some sort of bias in the spreads exists for a reason. As set out in part one, the most obvious reason is because bookmakers are manipulating their spreads to exploit bettors.
There are unfortunately three caveats. Firstly, the p-value associated with the 10-points handicap threshold, 1.7%, is less statistically significant, whilst the one for the 8-points handicap threshold, 25.2%, is not statistically significant at all.
Secondly, the use of the t-test may not actually be appropriate in this case, given we are dealing with counts of data (the number of time teams cover spreads) which may not conform to a known data distribution. Instead we can use the more robust but less powerful nonparametric distribution-free chi-square test. The chi-square p-value for the 12-points handicap threshold, for example, is 3.3%.
The more confidence a bettor has that a team will win (the greater the perceived favouritism), the more likely it is that they will also believe that the team will cover the point spread.
Finally, it is not at all obvious which points handicap we should consider when searching for a bias. By choosing different points handicap thresholds to test after we have plotted the data, we run the risk of arbitrarily choosing values that help us fit the hypothesis to the data, when we should really be fitting the data to the hypothesis. Such data mining is never a good idea. Bettors looking to ‘discover’ profitable systems this way do so at their peril.
In the extreme we could calculate a p-value for every point in the series of ranked points handicap values. Here this would mean 15,310 of them. This creates a multiple comparisons problem, where we perform a set of statistical tests simultaneously, each of which has the potential to ‘discover’ a meaningful inference. For example, if one test is performed at a critical p-value (threshold of statistical significance) of 5% level and the null hypothesis – that nothing but chance is operating – is true, there is only a 5% chance of incorrectly rejecting the null hypothesis.
However, if 100 tests are conducted where all corresponding null hypotheses are true, and the tests are statistically independent from each other, the probability of at least one incorrect rejection is 99.4%. We can’t then have much faith in our hypothesis testing unless we apply some sort of correction.
One commonly used method is the Bonferroni correction. To perform a Bonferroni correction, one simply divides the critical p-value by the number of comparisons being made. For example, if the critical value for a single test was 5%, with 10 simultaneous tests that would reduce to 0.5%. If none of the 10 p-values fall below that more demanding threshold, we would be unable to rule out the null hypothesis that everything we are seeing just happened by chance.
The next chart shows the evolution of p-value for the t-test and chi-square test for consecutive cumulative match samples in the series ranked by points handicaps. The y-axis is logarithmic. Also shown is the Bonferroni correction critical p-value assuming that the critical value for one test 5% and there were 15,310 simultaneous tests performed.
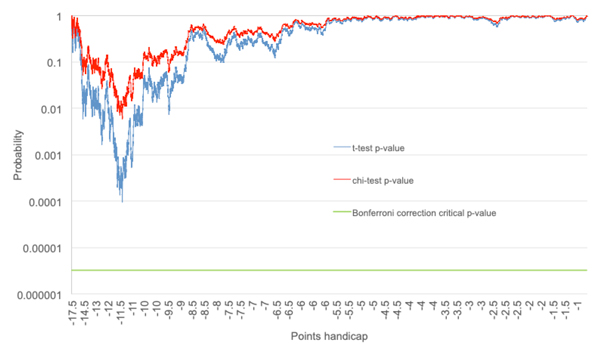 The nonparametric chi-square tests show systematically more conservative p-values and are probably the more appropriate ones to pay attention to. Yet even for the t-test p-values there was not a single figure that achieved the corrected critical value that might permit us to rule out chance as the only reason we are seeing what we see.
The nonparametric chi-square tests show systematically more conservative p-values and are probably the more appropriate ones to pay attention to. Yet even for the t-test p-values there was not a single figure that achieved the corrected critical value that might permit us to rule out chance as the only reason we are seeing what we see.
Strictly speaking the Bonferroni correction assumes that all the simultaneous tests are independent of each other. Evidently in a ranked series of points handicaps where we are progressively trying to find out if consecutively larger samples of favourites are collectively covering the spread less than 50% of the time, this will not be the case. Hence, our corrected critical threshold is likely to be far too conservative. Nevertheless, I have illustrated this methodology to highlight the potential pitfalls of assuming statistical significance when it might not actually exist.
What have we learnt from this analysis?
Speaking qualitatively, I would summarise these findings as follows. Yes, there does appear to be a point spread favourites bias in an NBA betting market, but it only really exists for the largest of handicap values. If there is any statistical significance to this bias implying a causal reason beyond chance for why it exists, for example spread manipulation by the bookmaker, then it is likely to be weak.
If bookmakers are manipulating the spread in the way Levitt suggested they do for NFL, such manipulation is limited in scope. Intuitive bias might explain why bettors over-bet the largest of handicaps, but if they do the bookmaker can only exploit this in the most minimal of ways. Try to exploit it more by shifting the spreads further and bettors’ behaviour will probably respond nonlinearly, removing any additional profit expectation the bookmaker had hoped to make.
Had you bet against the favourites in this 12-season sample as a contrarian might do, here’s how your yield would have evolved with ranked points handicap assuming prices of 1.95 (-105) and a bookmaker’s margin of 2.5%.
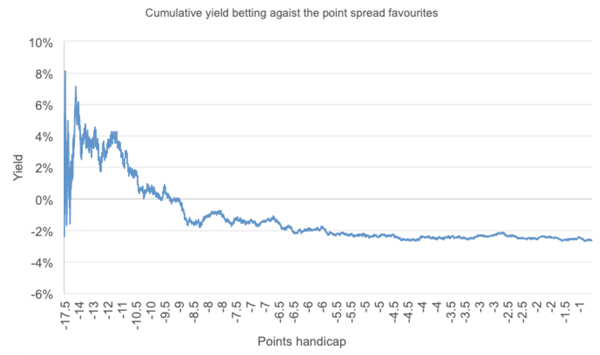
Yes, there is potentially some profitability to be had being the contrarian and backing the largest underdogs to cover the spread. Nevertheless, it’s small, and questions remain whether it really is statistically significant and therefore persistent into the future. Much as for the favourite–longshot bias in fixed odds betting markets, what potential profitability exists because of its presence is limited to betting against the strongest of favourites only, whilst most of the market lies well within the risk tolerances set by the bookmaker’s margin.
Most certainly there is no difference between all favourites and underdogs more generally across all spread values; they cover the spread just as much as each other. Whilst pockets of inefficiency might exist for the strongest favourites, on average NBA spread prices appear to be very representative of the true probabilities of teams covering those spreads.
If any more general bias once existed at a time that Levitt was studying NFL markets, it would seem to have largely disappeared. Once inefficiencies become public knowledge, they will usually have only a limited shelf life.
![]()
MORE: TOP 100 Online Bookmakers >>>
MORE: TOP 20 Cryptocurrency Sportsbooks >>>
MORE: Best E-Sports Betting Sites >>>
Source: pinnacle.com